Building a Generative Q&A Engine with Semantic Search and Embeddings
In the age of AI-powered tools and intelligent systems, the ability to search, analyze, and generate insights from documents has become paramount.
Senthilnathan Karuppaiah
Introduction
In the age of AI-powered tools and intelligent systems, the ability to search, analyze, and generate insights from documents has become paramount. Semantic search and generative AI offer powerful capabilities to build engines that allow querying large sets of documents, answering questions naturally, and even recommending relevant content. This article is part one of a multi-series guide to building such a system.
::list{type="success"}
- Part 1: Generative Q&A Engine with Semantic Search and Embeddings (this article)
- Part 2: Semantic Search and Document Recommendations
- Part 3: Q&A Chat and Document Enhancements Using GenAI ::
This implementation extends TemplrJS, my open-source, full-stack rapid app development framework built on Nuxt.js and Supabase, to enable Generative AI and RAG applications. While designed within TemplrJS, this system is versatile and can be seamlessly adapted to any JavaScript-based framework. The solution prioritizes simplicity, scalability, and cost-effectiveness by leveraging open-source tools and free-tier services, making it an ideal starting point for AI-powered
Use Case(s)
- Document Retrieval: Efficiently retrieve documents based on semantic meaning rather than keyword matching.
- Generative Q&A: Provide contextual answers to user queries based on the content of documents.
- Vector Search for Content Recommendation: Suggest related documents by leveraging cosine similarity on vector embeddings to identify and retrieve semantically similar content.
- Future Use Case: Semantic Impact Analysis for Test Case Management: Extend this approach to perform impact analysis for large-scale engineering projects or products. By leveraging semantic content matching on well-written test cases, it is possible to identify affected test cases and create an impact lineage graph. This can further be enhanced using generative AI to automatically generate new test cases or refine existing ones based on the identified impact.
Ingredients

Technical Architecture and Design
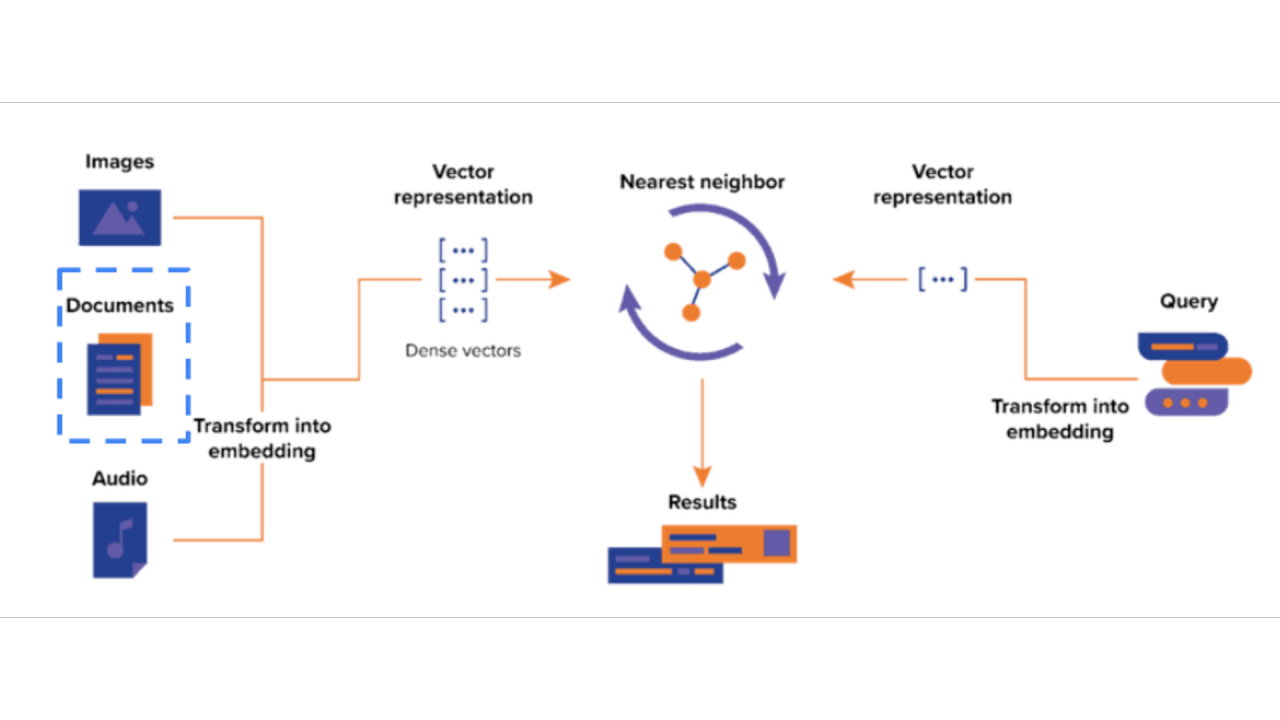
Text Embedding/Vectorization Workflow
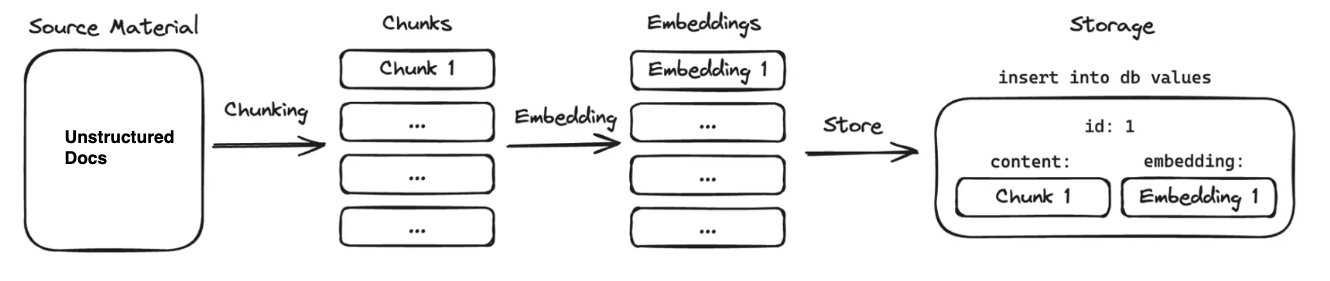

Retrieval and Query Response Workflow

Entity-Relationship Diagram (ERD)

::list{type="success"}
- The Documents table has a one-to-many relationship with the DocumentSections table.
- The docId in the DocumentSections table references the id in the Documents table. ::
Data Dictionary
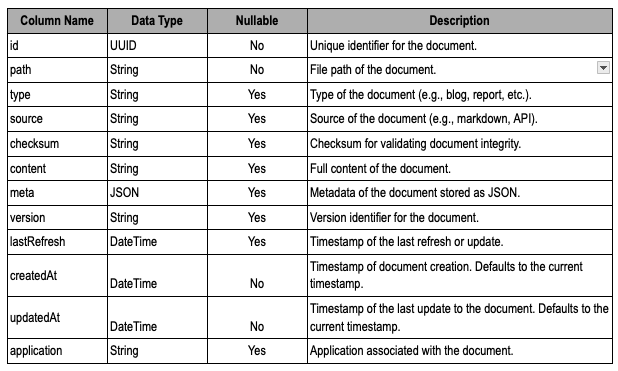
Documents Table
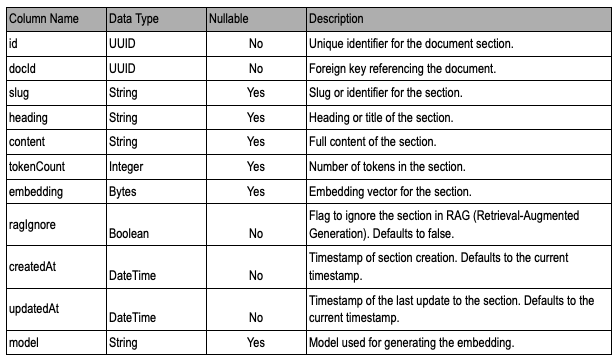
DocumentSections Table
Key Features
::list{type="success"} Chunking and Tokenization: Efficiently chunk documents with token overlap for context retention. Embedding Generation: Generate dense vector embeddings for each chunk. Database Integration: Store document metadata and embeddings in Supabase Postgres with pgvector. Swappable Models: Easily switch between models like nomic-embed-text | text-embedding-ada-002 | bge-large etc. for embeddings and llama3.2 | gpt-3.5-turbo | Mistral etc. for Text Generation. Batch Processing: Log and summarize successes and failures for observability. Future Proofing: Support for additional use cases such as test case management and content generation. ::
Source Code
TBD: Will be added/linked shortly
Python version: Jupyter Notebook
JavaScript version:
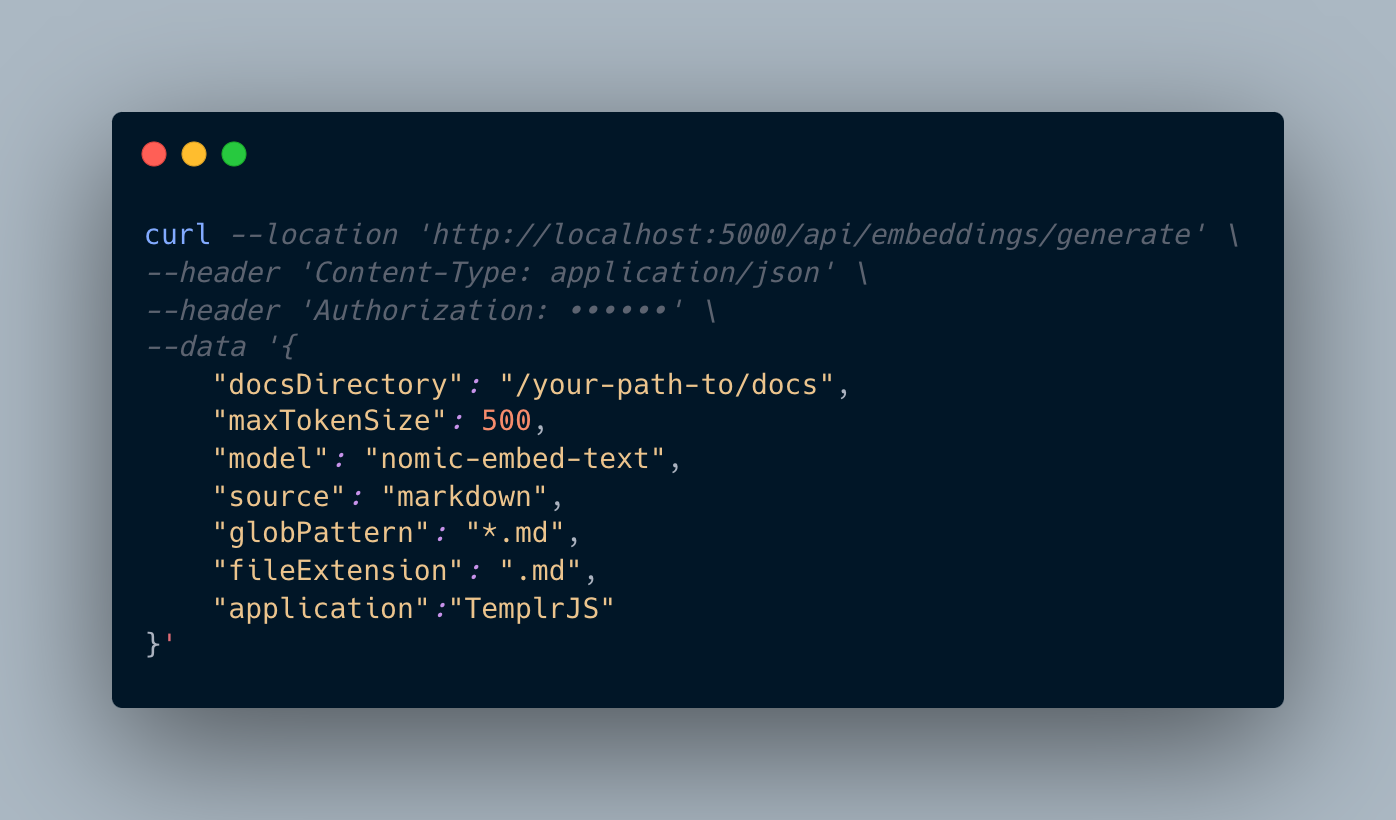
REST API: Embedding Generation
Endpoint: POST /api/embeddings/generate
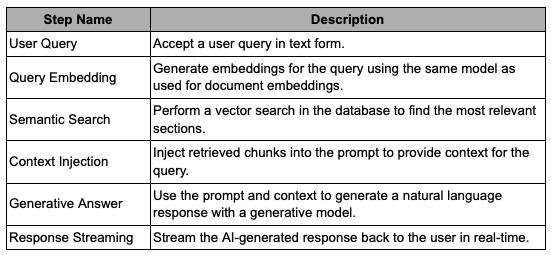
Next Steps
Stay tuned for Part 2: Semantic Search and Document Recommendations, where we’ll cover retrieval mechanisms and cosine similarity for document suggestions.
Credits and References
::list{type="success"} ClippyGPT - How I Built Supabase’s OpenAI Doc Search (Embeddings) https://youtu.be/Yhtjd7yGGGA?si=5dxX8cziMWnCG5qj ::